
Stephen Baxter's
Website
Work History
Student Worker - DMS Specialist,
June 2021 to present: Center for IT Excellence,
Texas A&M University-Commerce, Commerce, Texas
Designing, creating, testing, and implementing Laserfiche forms
Mentor,
Fall of 2021 to present: Atypical Ambassadors,
Texas A&M University-Commerce, Commerce, Texas
Help mentor two students, with school work, coping with problems, and being there if they need someone to talk to.
Volunteer,
Summer of 2021: Rains County Good Samaritans,
Emory, Texas
Moving, sorting, and shelving donated items for resell.
Technical Skills
Languages: JavaScript, HTML5, CSS, Python, C/C++, C#, Visual Basic
Artificial intelligence: Q learning, Deep q learning, Artificial neural networks
Operating Systems: Linux, Microsoft Windows
Development Tools: JQuery, Laserfiche, Visual Studio Code, Visual Studio 2017-2022, Dev-C++
Server Software: MySQL, SQL, ASP.NET
Productivity Software: Microsoft Word, Excel, PowerPoint, LibreOffice, Google Workspace
Education
Master of Science in Computer Science - Summa Cum Laude GPA 3.91, January 2020 - May 2023 Texas A&M University-Commerce, Commerce, Texas
Bachelor of Science in Mathematics with Minor in Computer Science - Cum Laude GPA 3.54, January 2015 - December 2017 Texas A&M University-Commerce, Commerce, Texas
Associate of Science in Mathematics - Magna Cum Laude GPA 3.78, August 2012 - December 2014 Tyler Junior College, Tyler, Texas
About This Website
Greetings
Hello and welcome to this website. The purpose of this website is two fold: to provide demonstration and a easy way to navigate my repos. To navigate this website please use the menu on the left side of the site, if the site is in reduce or mobile mode the the menu will retract and a menu icon will appear in the top left corner. Along the top in the center is a shortcut to the homepage of this site and on the right is a ling to my GitHub and LinkedIn.
Building
This Website was primarily made with Visual Studio Code for coding; Google Chrome, Microsoft edge, and Firefox for debugging, GIMP for art work, and GitHub Pages for hosting. Along with software the libraries used are JQuery for streamlining the code, ThreeJS for the render in the background of the homepage, and JakGameEngine which is a custom library created and use for handling user input, timing for canvases, drawing sprites, shapes, and text to canvases, and rendering methods such as wire-frame or ray-casting.
Pages
Note: although this website does not have flashing light, some of the demonstration have moving part so please be aware.
The "Research Paper" page presents information about the research paper I was the lead researcher on along with the paper it's self
The "AI Demonstration" page shows a working demonstration of a program using Q-Table reinforcement learning machine learning with a explanation of how Q-Table reinforcement operates.
The "Project Demonstrations" page provides interactive demonstrations along with some description on how they work.
The "Project List" page gives a sortable list of repo read-mes from my GitHub, the read-me are requested directly from GitHub with Ajax so minimum changes have to be made to this website when a new repo is added.
Appreciation
Lastly, thank you for visiting this website,
Stephen Baxter.
Stephen Baxter's Resume
Hello and welcome, below is a copy of my resume.
Research Paper
Cheshire: A New Believable Chat Bot Using AIML, LSA, Emotions from Personalities, and Voice Recognition and Synthesizer
Hello and welcome below is some information about Cheshire. This paper was started for the CSCI 595 Research Lit & Techniques course as part of my master degree. With help from my professor Sang Suh, PH.D. the paper was continued, reworked, and improved for publishing. The paper was published by the 57th Hawaii International Conference on System Sciences.
Title:
Cheshire: A New Believable Chat Bot Using AIML, LSA, Emotions from Personalities, and Voice Recognition and Synthesizer
Abstract:
Since the 1950s, people have been trying to create a more believable chatbot. The Standard Turing Test (STT) has generally been used to test them. Development of chatbot initiated with pattern recognition with Eliza in 1966 and PARRY in 1972, further with AI by Jabberwacky, and AIML with ALICE in 1995. Since then, people have tried adding nonverbal features, personalities, and audio input and output features. The goal of this research is to use these advancements to create a chatbot believable enough to pass the STT. To do this in a different way than most other chatbots, this new chatbot will use AIML with LSA to generate a response, derive and use the emotional ton of the user input along with a selected personality to apply an emotional ton to the response, and provide a means for the user to talk to the chatbot and for the chatbot to talk back.
Link:
https://hdl.handle.net/10125/107013
AI Demonstration
Racecar Dodging
Demonstration
Q-Table
| State \ Action | turn left | keep going straight | turn right |
| State 1 | 0 | 0 | 0 |
| State 2 | 0 | 0 | 0 |
| State 3 | 0 | 0 | 0 |
| State 4 | 0 | 0 | 0 |
| State 5 | 0 | 0 | 0 |
| State 6 | 0 | 0 | 0 |
| State 7 | 0 | 0 | 0 |
| State 8 | 0 | 0 | 0 |
| State 9 | 0 | 0 | 0 |
| State 10 | 0 | 0 | 0 |
| State 11 | 0 | 0 | 0 |
| State 12 | 0 | 0 | 0 |
| State 13 | 0 | 0 | 0 |
| State 14 | 0 | 0 | 0 |
| State 15 | 0 | 0 | 0 |
| State 16 | 0 | 0 | 0 |
| State 17 | 0 | 0 | 0 |
| State 18 | 0 | 0 | 0 |
| State 19 | 0 | 0 | 0 |
| State 20 | 0 | 0 | 0 |
| State 21 | 0 | 0 | 0 |
Instructions
Hello and welcome, above is a live demonstration of an AI using Q-learning to learn how to play a game where the goal is to dodge incoming racecars.
For controls to pause demonstration click the “Pause” button, to reset the demonstration with new values then change settings and click the “Reset” button, and to play the game your self click the “AI” button.
Settings
Reward for dodging: is the reward for dodging incoming cars (default is 20).
Reward for hitting: is the reward for failing to dodge a incoming car (default is -200).
Chance of taking random action: is a number between 0 and 1 that denotes the chance that the AI will take a random action with 0 meaning no random action will be taken and 1 meaning a random action will always be taken (default is 0.01).
Alpha (a): is a number between 0 and 1 that denotes the rate that the AI will learn with 0 meaning no changes will be made to the related Q-value and 1 meaning all of the TD Error will be added to the Q-value (default is 0.0001).
Gamma (y): is a number between 0 and 1 that denotes the discount factor for the AI with 0 meaning the AI will always prioritize immediate reward and 1 meaning the AI will always prioritize future reward (default is 0.8).
Description
Figure 1
Q-learning is a reinforcement learning algorithm that learns an optimal policy for an agent to act in an environment. The algorithm iteratively updates a table of values, called the Q-table, that estimates the expected future reward for each possible action in each possible state. The agent chooses the action that maximizes the Q-value for its current state, and receives a reward from the environment. The reward is used to update the Q-table according to a learning rate and a discount factor. The learning rate determines how much the new information overrides the old information, and the discount factor determines how much the agent values future rewards over immediate rewards. Q-learning is an off-policy algorithm, meaning that it learns the optimal policy regardless of the agent's actual behavior. Q-learning can handle many simple environments, but it suffers from high computational complexity and slow convergence. In the case of this demonstration, the JavaScript library JakQTableBrain.js that I created is used with Figure 1. showing the complete code.
Key Terminologies in Q-learning
Figure 2
Q-Table: is a table of Q-Values of sets of states and actions. In the case of this demonstration, a Q-table is displayed and is constantly updating.
States (S): the current position of the agent in the environment. In the case of this demonstration, the agent's position can be 0 (left), 1 (center), or 2 (right). The environment is the cars if any that are in front of the agent: “0,0,0”, “0,0,1”, “0,1,0”, “0,1,1”, “1,0,0”, “1,0,1”, or “1,1,0” (the ones represent a car). Figure 2. shows the code used to find the state. We have 21 states in total.
Action (A): a step taken by the agent in a given state. In the case of this demonstration, there are three actions the agent can take: turn left, keep going straight, or turn right.
Rewards (Rt+1): is the immediate reward, for every action the agent is given a reward. In the case of this demonstration, the default reward for dodging is 20 while the reward for hitting is -200.
Episodes (t)/(t+1): the end of the stage with (t) is a time during a given episode before a action is taken and (t+1) is a time during a given episode after a action is taken. In the case of this demonstration, a episode is 30 ticks long with one tick being around one frame and the demonstration runs at 30 frame per second so a episode is about a second long.
Q(St, At): it is the Q-value in the Q-table at the State and Action at the beginning of the Episode. this is given by the Bellman equation which is in the form Q(St, At) = E[(Rt+1)+y*(Rt+1)+(y^2)*(Rt+1)+...|St, At], with E[(Rt+1)+y*(Rt+1)+(y^2)*(Rt+1)+... as the expected discounted cumulative reward and St, At] as the given state and action.
maxA'Q(St+1, A'): is the larges Q-value for the given State after a Action has been taken. When multiply by gamma (y) this gives the discounted estimate optimal Q-value of the next state.
TD Target: is the discounted estimate optimal Q-value of the next state added to the immediate reward.
TD Error: is the Q(St, At) subtracted by the TD Target.
newQ(St, At): it is the new Q-value in the Q-table at the State and Action.
Implementation
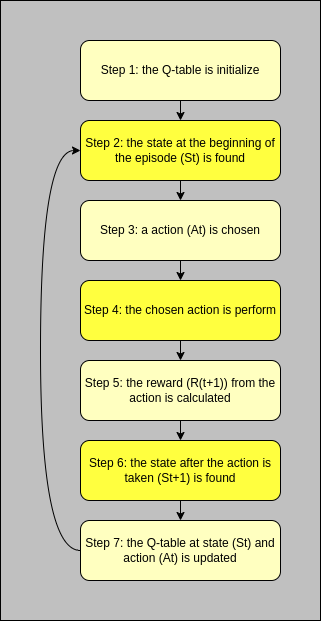
Figure 3
Figure 4
Figure 5
Figure 3. shows the flow chart for how Q-learning is implemented
Step 1: the Q-table that holds the Q-values is initialize with zeros using the number of states for the number of rows and the number of actions for the number of column.
Step 2: the state before any action taken (St) is found and stored.
Step 3: a action (At) is choosen. A random action may be chosen to be used to try and see if there is a better action for a given state, this is because Q-learning may fixate on a particuler action for a given state instead of the most optimal action for the given state. When a random action is not taken, the action qerlarating to the highest Q-values for the given state is chosen. Figure 4. shows the code from JakQTableBrain.js that does the operation.
Step 4: the chosen action is perform and the environment is updated as needed.
Step 5: after the action is taken a reword (R(t+1)) is calculated, with a higher reward given for more preferable actions taken in a given state.
Step 6: the state after a action is taken (St+1) is found and stored.
Step 7: the Q-value at state (St) and action (At) is updated with the function newQ(St, At) = Q(St, At) + a * ( R(t+1) + y * maxA'Q(St+1, A') - Q(St, At) ). Figure 5. shows the code from JakQTableBrain.js that does the operation.
After Step: 7 the flow repeats starting at Step: 2 for a new episode.
Conclusion
Q-learning can be use to provide learning capability to a program with simple parameter but may have problems with more complex scenario. The scenario used in this demonstration of a agent learning to drive a racecar through incoming cars only has 21 states and 3 actions for a total of 63 (21*3) Q-values that most be updated. With more complex scenario more Q-values will need to be updated before results can be seen in the agent.
Thank you for reading this.
Project Demonstrations
Hello and welcome, below is a list of demonstration to choose from.
Note: although this website does not have flashing light, some of the demonstration have moving part so please be aware.
STICK
GitHub Projects List
Hello and welcome, below is a list of readme to choose from.
Note: depending on your internet connection this may take a few seconds